 Why are distributed transactions icebergs? It’s not because they’re cool and beautiful and you have to look under the surface to comprehend them.
Why are distributed transactions icebergs? It’s not because they’re cool and beautiful and you have to look under the surface to comprehend them.
Distributed transactions are icebergs because (1) it’s easy to not see them, even when they’re right in front of you, and (2) if you run into one, it’s got a great potential to sink your ship.
Distributed transactions are icebergs: they can be hard to see, and they can sink your ship.
Click To Tweet
What is a distributed transaction?
I’m not talking exclusively about explicit distributed transactions, vis-à-vis your old XA standard. My definition of a distributed transaction is simple:
distributed transaction (n.) any situation where a single event results in the mutation of two separate sources of data which cannot be committed atomically
In microservices, the temptation to do this pops up all the time. Like, right under your nose, and you may not even see it. That’s the first reason why they’re icebergs.
What’s wrong with distributed transactions in microservices?
 The problem with distributed transactions is that they’re a time bomb for the optimist… but, without the user-friendly countdown. For those who think mostly about the happy paths in their system, distributed transactions will lie in wait, showing no harm day by day, until a little glitch happens in your network and suddenly all hell breaks loose.
The problem with distributed transactions is that they’re a time bomb for the optimist… but, without the user-friendly countdown. For those who think mostly about the happy paths in their system, distributed transactions will lie in wait, showing no harm day by day, until a little glitch happens in your network and suddenly all hell breaks loose.
Here’s the thing: a distributed transaction is about having one event trying to commit changes to two or more sources of data. So whenever you find yourself in this situation of wanting to commit data to two places, you have to ask:
“Would it be okay if the first commit succeeds and the second fails?”
And I propose that about 98% of the time, the answer will be “Hell, no!”

But failure will happen. If you’re familiar with the fallacies of distributed computing, you know it will happen. (If you’re doing microservices and you’re not familiar with the fallacies – stop everything and go learn them now! I’ve posted them on the walls at work to make sure people don’t forget.)
If you have distributed transactions, then when those fallacies come home to roost, you’ll end up committing data to only one of your two sources. Depending on how you’ve written your system, that could be a very, very bad situation.
Distributed transactions might be great if the fallacies of distributed computing weren't false.
Click To Tweet
Distributed Transaction Examples Hiding in Plain Sight
So I said they might be right under your nose. Let’s have a look at some examples.
Here’s a simple microservice system for buying a book online using the book store’s proprietary payment credits.
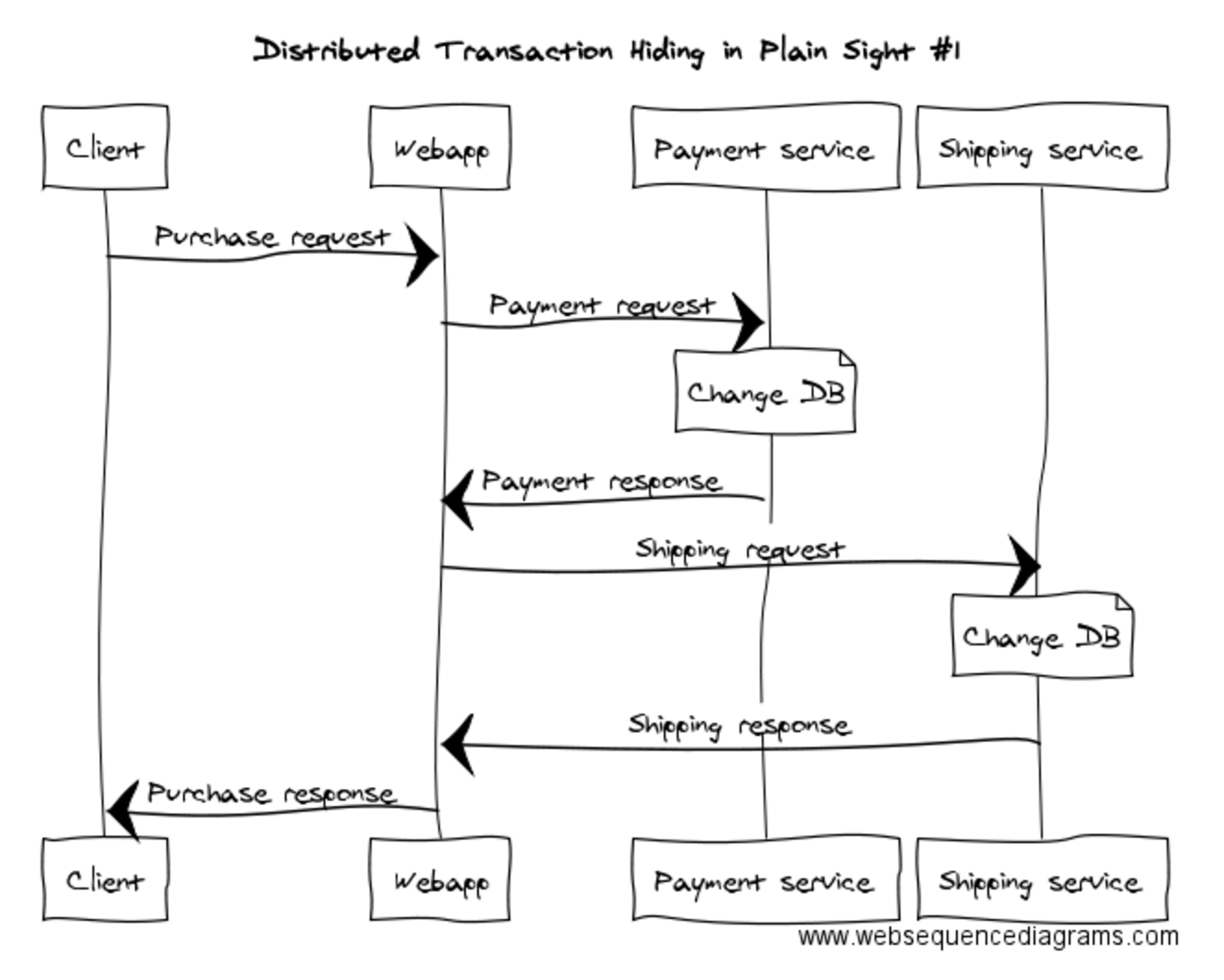
We have a Webapp, a Payment service and a Shipping service. The Webapp does the coordination: it asks the Payment service to debit the account, and when it’s heard back about that being successful, it tells the Shipping service to ship the book. What happens if the payment succeeds but the Shipping service isn’t up? Bzzzzzzz. You’re out of luck.
Can’t we do something about that? Maybe we can reverse the payment? Well, we could try that, but can we guarantee that we can reverse the payment? Maybe we can give the Webapp a database and store in there the fact that there’s a pending shipment that’s paid for? Well, we could try that, but can we guarantee that the Webapp’s storage is available after the payment’s completed? We can put layers and layers of error handling in here, and we could narrow the window for error to be smaller and smaller, but we’ll never get to a solution that’s robust.
Maybe the architecture’s wrong? What if we put the Shipping service in charge of things? Like this…
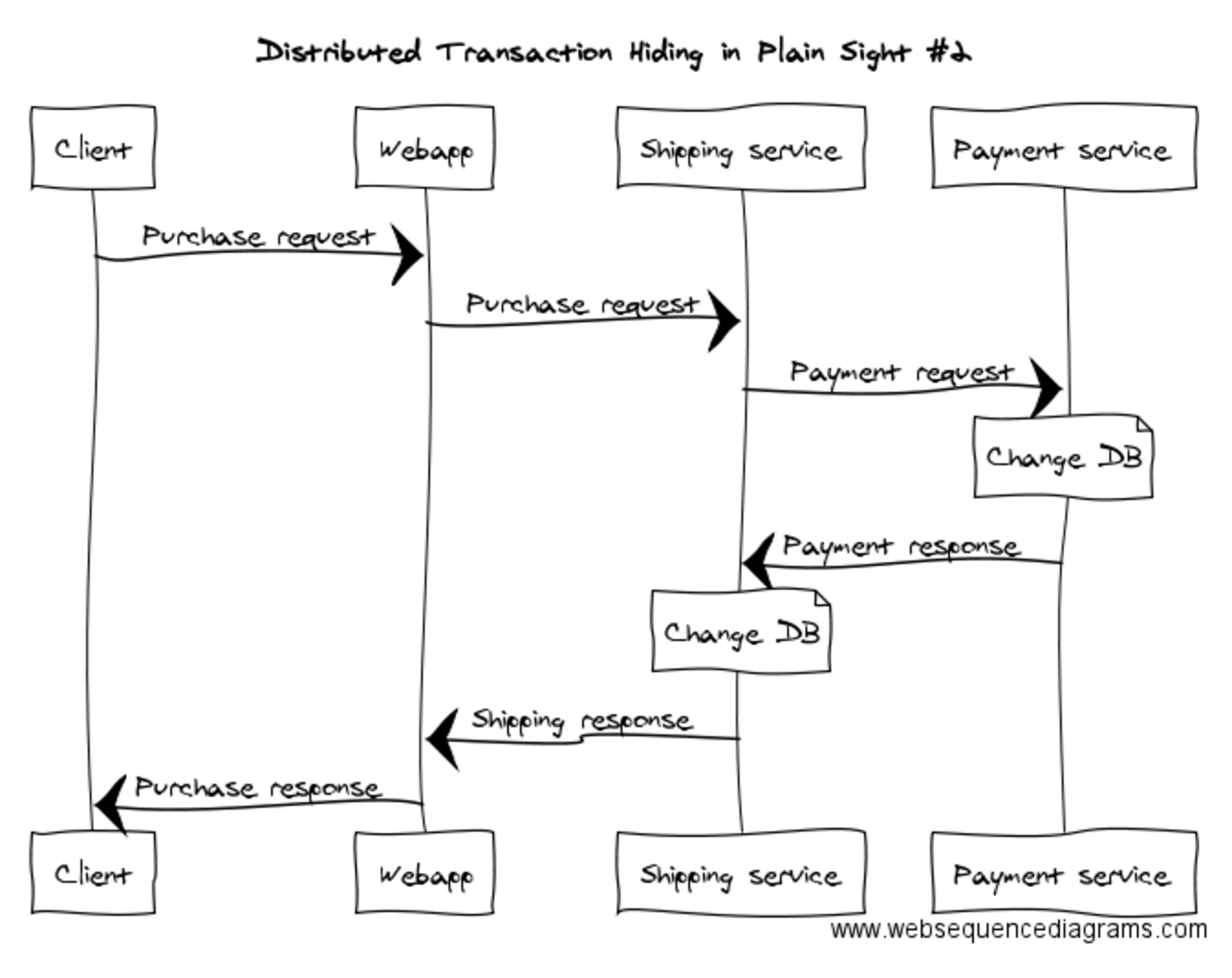
Looks like it might be better, but it’s still got the same problem: the Payment service may complete successfully but the Shipping service can still fail. It might fail to receive the response because the network flakes, fail to still be running when the Payment service tries to respond, or fail to contact its database to commit the shipment. It’s the same iceberg viewed from a different angle: it’s a distributed transaction.
Distributed Transactions: Not Just About Databases
Here’s another example at a somewhat lower level. Let’s say we’re using a message broker to communicate between services. An event occurs prompting a call to some service and we want to change some data in the local service and send a message to one or more remote services:
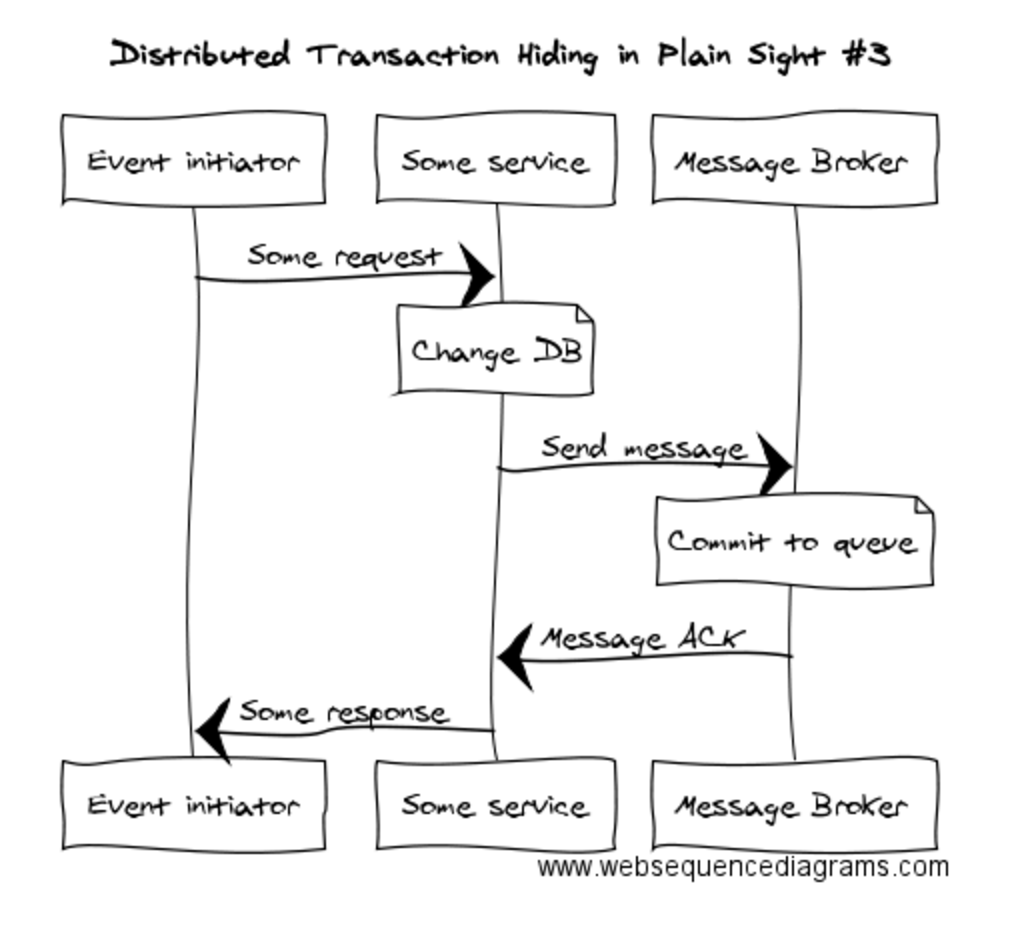
The important thing to realise here is that the message broker is also a data source. See that “Commit to queue” bit? That’s the message broker changing its data source. Hence, this is another example of a distributed transaction.
Again, let’s ask ourselves the important question: If we saved the data to the database but then couldn’t send the message, would we be happy about that? Conversely, if we sent the message but then failed to save to the database, would we be happy about that?
Distributed Transactions: The Solution
The solution to distributed transactions in microservices is simply to avoid them like the plague.
Click To Tweet
 Just agree as a team to not go down this road.
Just agree as a team to not go down this road.
How do you avoid them and still get your microservices coordinating? It’s actually quite simple: every business event needs to result in a single synchronous commit. It’s perfectly okay to have other data sources updated, but that needs to happen asynchronously, using patterns that guarantee delivery of the other effects to the other data sources.
How do you implement this? Quite simply, you have to pick one of the services to be the primary handler for the event. It will handle the original event with a single commit, and then take responsibility for asynchronously communicating the secondary effects to other services.
When you find yourself in a real-life version of this situation, which service to choose to be the primary handler will not always be obvious. There will be trade-offs. In our example, you could do it like this, where the Shipping service is responsible for executing the payment asynchronously:
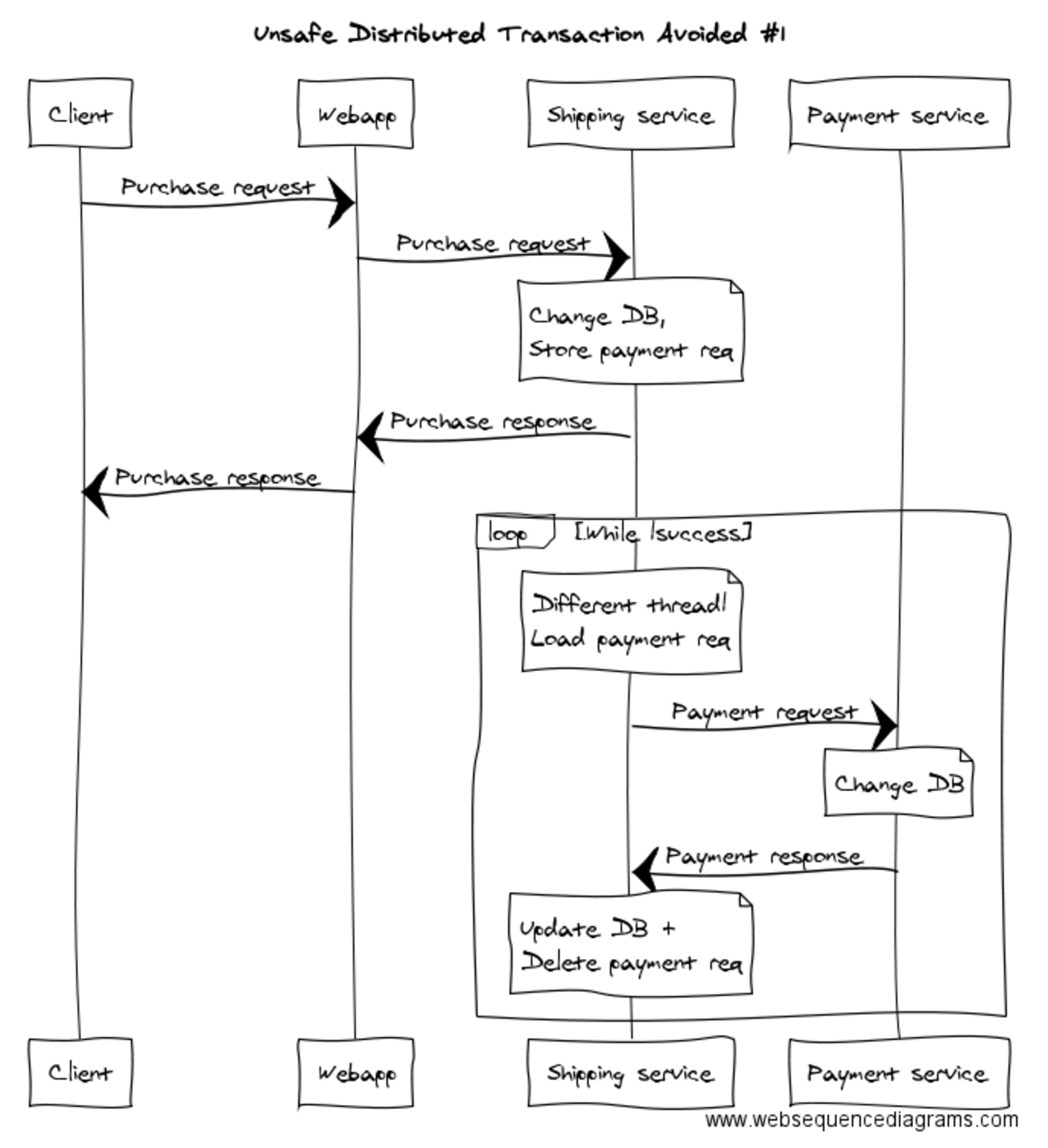
Or you could do it like this, where the Payment service is responsible for notifying the Shipping service asynchronously (and before you spend too much time reading this one, yes, it is a straight swap of the words “Payment” and “Shipping” in the above diagram):
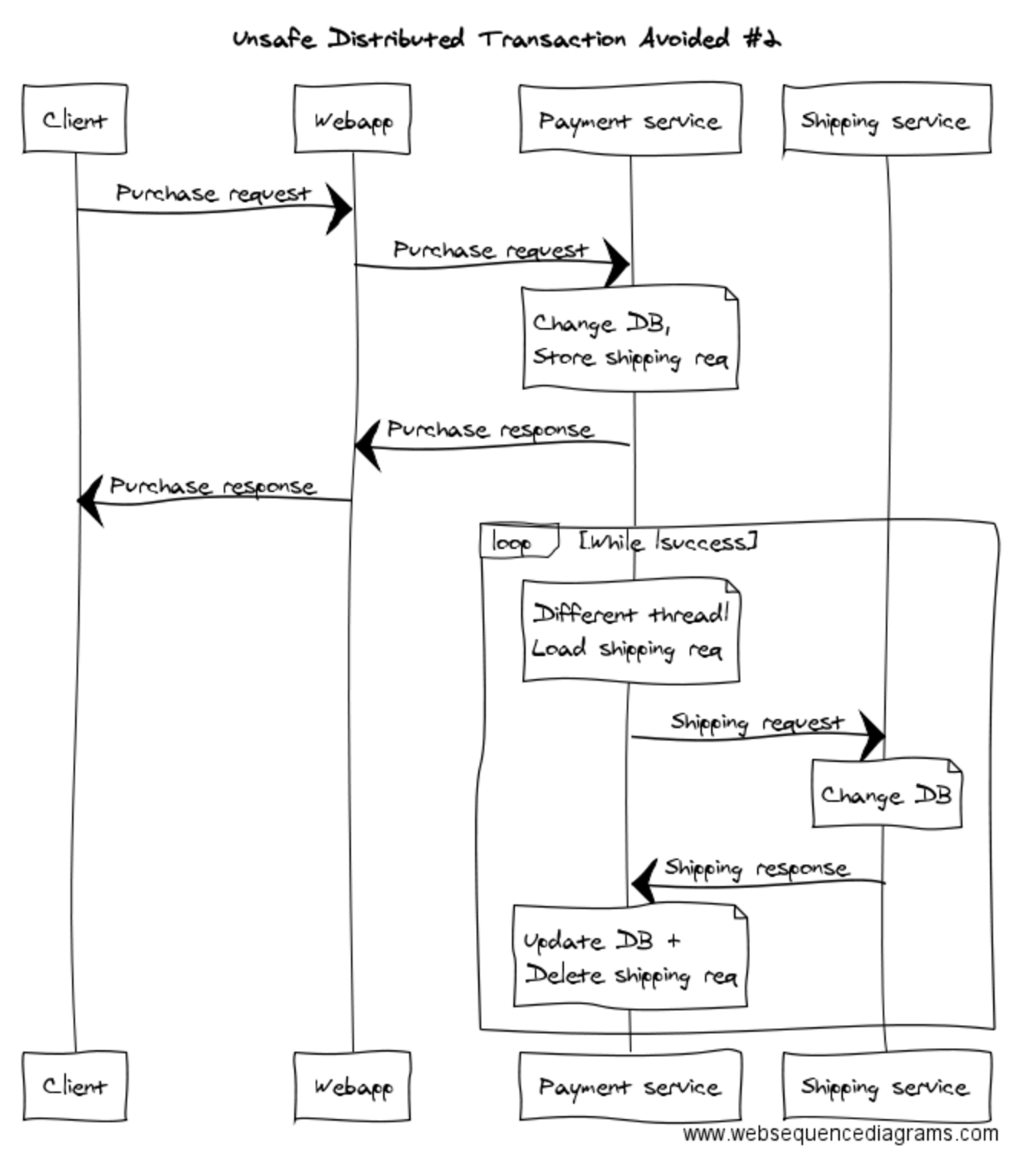
The key, if you didn’t pick it up, is that things happen asynchronously – on another thread, in another transaction. Notice that in the original transaction the Payment service is saving, in the same data store as its business data, the fact that it needs to notify the Shipping service. Another thread then picks the item off the queue and contacts the Shipping service. Once the Shipping service responds with success, we remove the item from the queue in the Payment service.
Hold your horses! Did you just say that after one database commits a transaction, we’ll commit something to the other database?
Yes I did.
But isn’t that a distributed transaction?
Why, yes it is. Which leads us to…
The Distributed Transaction That’s Okay
Let’s go back to the core problem with distributed transactions, which is that the answer to the question – “Would it be okay if the first commit succeeds and the second fails?” – is almost always “No!”. Well, in order to make this whole thing work, we have to create situations where the answer to that questions is, “Yes, everything will be fine.”
The way to achieve this is with the combination of a commander, retries and idempotence.
Safe Distributed Transactions: Commander, Retries and Idempotence
The commander is in charge of the distributed transaction. It knows the instructions that have to be executed and will coordinate executing them. In most scenarios, there will just be two instructions:
- Effect the remote update.
- Remove the item from the commander’s persistent queue.
The pattern can be extrapolated to work for any number of instructions, though, for example in the case of a multi-step orchestration component.
Secondly, the commander needs to take responsibility for guaranteeing the execution of all instructions, and that means: retries. In the case that the commander tries to effect the remote update and doesn’t get a response, it has to retry. If the commander gets a successful response but fails to update its own queue, then when its queue becomes available again it needs to retry. There’s other failure scenarios. The answer is retry.
Thirdly, because we have retries, we now need idempotence. This is a big word for a very simple thing. It’s just the property of being able to do something twice and have the end result be the same as if it had been done once. We need idempotence at the remote service or data source so that, in the cases where it receives the instruction more than once, it only processes it once. We don’t want to ship the book twice just because the Payment service timed out before receiving our first response! This is typically achieved with some simple duplicate detection based off a unique identifier in the instruction.
Once we’ve done all this, we have a robust distributed transaction through guaranteed delivery, however it’s important to realise that it’s not an atomic transaction. We’re completing one unit of work across two data sources, so it’s possible that the work has been completed but the record that it’s been completed (the pending queue item) may be out of sync when there are failures in the system.
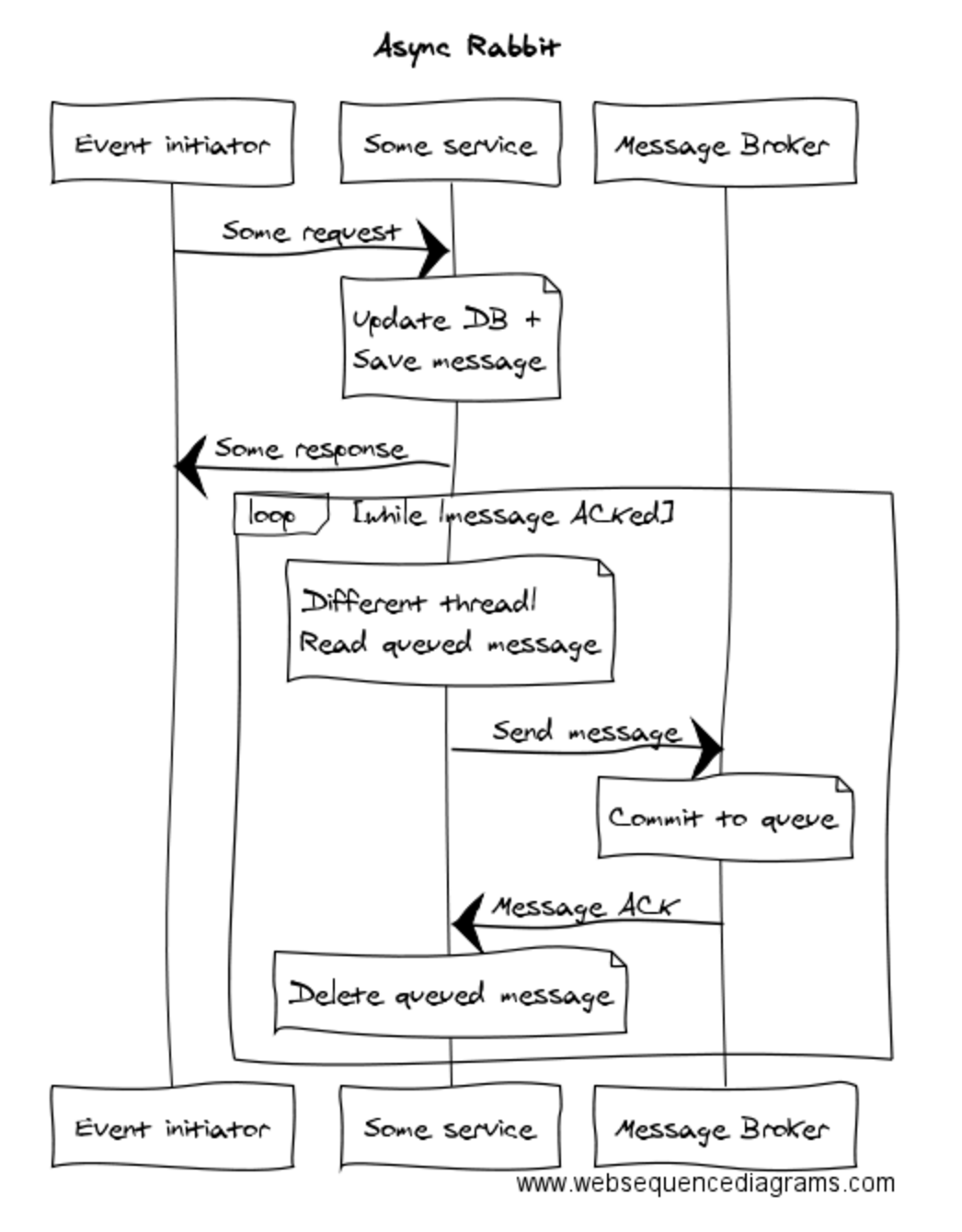
At Tyro, where we currently do a lot of communication through RabbitMQ, we have a pattern we call “Async Rabbit”. The “Async” part is there not because because of the asynchrony introduced by using a message broker, but because we are submitting messages into the message broker asynchronously within the application, so as not to create a bad distributed transaction. The pattern looks like this:
The Big Trade-Off
Let’s go back to the core of this solution: a single synchronous commit, with asynchronous commits for the secondary effects. It’s super important to realise that, by employing this method, we’re introducing eventual consistency into the system.
The Payment service does not know whether the Shipping service is up when it processes the payment. It does the payment, commits to guaranteeing the secondary effect of contacting the Shipping service will happen, and returns “Success” to the user via the Webapp. Now, we hope that most of the time the Shipping service will be up and running and that the shipment will be processed milliseconds after the payment, but if the Shipping service is down for a minute, or an hour, or a day, or longer, that just has to be okay.
This is eventual consistency: eventually the effects of that primary commitment will permeate through the system, but it will take an amount of time that is non-zero. If you’re going to go down this road, you have to be cognisant that you’re introducing this characteristic to your system and be aware of the constraints it places on your software, in particular what you’re going to do when you have decisions that do require atomicity.
Two Consequences of Eventual Consistency
Let’s talk briefly about two consequences that this approach leaves you with.
Number one: We’re going to retry when we can’t get through. How many times, or for how long, do you retry? Answer: Depends on the context. One thing’s for sure, though – if you’re doing retries, it’s because something’s wrong in your system, so you’ll want to be monitoring that as it’s quite possibly a canary in the coal mine. The point of retries is to enable self-healing, but you’ll want to be aware that healing was required.
Number two: Because consistency is eventual, you can end up with what we might call business consistency conflicts. For example, let’s say a book was available when the “Purchase” page was shown to the user, but by the time the payment was processed and the Shipping request sent to the Shipment service, there are no copies left to ship. What to do? We’re asynchronous now, so there’s no reporting back to the user. What we need to do is recognise conflicts like this in the system and raise them up to be dealt with. This can be done either automatically, for example by refunding the user and sending an apology email, or manually, for example by queueing the conflicts as something to be dealt with by an employee.
Alternatives
 Are there alternatives for resolving this situation? Absolutely.
Are there alternatives for resolving this situation? Absolutely.
First alternative is to avoid needing distributed transactions. When you find you need to update data in two places as a result of one event, you can consider refactoring your architecture to move some of the data so that you can update it all in one place, in one transaction. This may be an appropriate approach every now and then to reduce the complexity of specific system journeys, but I doubt it’s one that you can employ regularly in a microservices architecture. If you take this step over and over again, every time you hit a distributed transaction, you’ll eventually coalesce everything into a single monolithic database! But you do have the option of using it where it has the most benefit.
Second alternative is to actually just do the unsafe distributed transaction and be prepared to handle error scenarios. To do that and not sink your ship, you need two things: (1) some detection in place in the form of a data reconciliation, and (2) you need to ensure that you’ve got all the data. That means it’s only okay for the 2nd and following legs of a distributed transaction to fail if the 1st leg contains all the data needed to execute the following legs manually once a mismatch has been found. This is mostly true of the async pattern advocated above anyway. The only real difference is that with async+retries, you get the probability of a self-healing system. With distributed transactions+detection of half-commits, you’ll need to handle each failure manually.
Finally, the third alternative is just to be an optimist and not worry about this stuff. Maybe you work on a system where it’s no biggie for an event to be half committed and not actually finish getting processed. At Tyro, we’re building a nextgen bank, so we think about guaranteeing things a lot, because that’s the expectation of our customers. When considering the impact that our context has on the way we design for this kind of stuff, we often use the motto, “No one cares if you lose one of their Tweets, but they care if you lose one of their dollars.”
Thanks to Chris Howard and Carl Francia for giving feedback on the draft version of this article.
Want to learn more?
  |
  |
  |
  |
Image credits: ‘Nature Antarctica 18‘ by Georges Nijs
‘Suitcase Bomb prop‘ by Rafael Mizrahi
‘Road Closed‘ – public domain
‘Sign for the roundabout between U.S. Route 50 Alternate, U.S. Route 95 Alternate and Nevada State Route 828 at the west end of Nevada State Route 828 (Farm District Road) in Fernley, Nevada‘ by ‘Famartin’
The post Distributed Transactions: The Icebergs of Microservices appeared first on Evolvable Me.

















